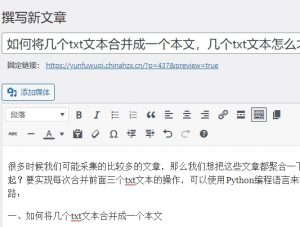
作为网站的seo人员可能很多时候我们都需要采集一些长尾词来给自己的网站获取更多的流量, 但是我们在拿到一份关键词的时候发现很多类似的关键词:

比如:
上面的关键词并不重复, 就是相似度比较高, 那么这个时候我们怎么才能删除一些相似度比较高的词? 其实也是比较的简单, 我们需要使用python 来实现, 如果你没有安装python环境, 那么我们需要先安装.
import Levenshtein
# 相似度阈值, 即两个文本相似度大于等于该值则进行去重操作
similarity_threshold = 0.8
# 读取文本文件中的所有行
with open('text.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
# 对文本列表进行去重
for i in range(len(lines)):
for j in range(i+1, len(lines)):
similarity = Levenshtein.ratio(lines[i], lines[j]) # 计算文本相似度
if similarity >= similarity_threshold:
lines[j] = '' # 将相似文本从列表中删除
# 将去重后的文本列表重新写入到同一文本文件中
with open('text.txt', 'w', encoding='utf-8') as f:
for line in lines:
if line != '':
f.write(line)
这里的话我们需要新建一个text.txt文件, 然后把上面的代码复制到py的的文本里面, 然后运行就会发现我们保存的数据如下:
这个时候我们在写文章的时候就可以写的关键词就不会重复率太高了. 当然你数据关键词比较多的时候处理起来可能需要等待一段时间.
上面的代码是什么意思? 可能很多小伙伴看不明白, 这里卡卡哥详细的说明下:
具体每行代码的语义如下: